1.背景
代码地址:Maicius/QQZoneMood
网站:QQ空间数据分析-小麦冬
最近出于兴趣,将QQ空间的爬虫程序进行了大量重构,将它从一个脚本程序变为了一个可以在线上运行的网络服务。这需要解决很多问题,其中最重要的就是时间效率问题,因为网络服务不能让用户等太久。而仅仅是获取一条QQ空间中的完整的说说内容,就至少需要发送5次请求,包括:1.获取说说目录(每页20条);2.获取说说详情(评论数量是20一页,超过20的需要再发送请求);3.获取点赞数量(好友昵称可能会缺失);4.获取详细点赞数据(可能有缺失);5.下载图片(包括小图、大图)。因此,在单线程的情况下,获取2000条说说数据且不包括下载图片的情况下大约要花费40分钟。此外,还要获取好友的数据,1500位好友单线程大约需要花费10分钟。显然速度过于缓慢,因此,为了提高效率,不得不从多方面开始重构。
关于python的并发,首先需要知道以下两点:
- 由于全局解释锁(GIL)的存在,python的多线程并不能做到真正意义上的并发。
- python的多进程可以做到真正的并发,进程和线程的区别很多。本文中主要关注其中两个特点:1.进程开销比线程大;2.进程间内存不共享,线程可以。
所以,在python中,对于普通的以计算为主的任务,多线程并不适用,可以考虑多进程;而对IO密集型任务,多线程和多进程都能有效提高效率。而爬虫,就是典型的IO密集型任务,爬虫程序中主要的时间消耗是发送http请求并等待响应这个过程。
再解释一下守护线程(Daemon Thread)的概念。在开启一个子线程之后,父线程有两种选择:一是等待子线程结束后再继续执行父线程,二是父线程直接继续执行,不管子线程。前者我们称为非守护线程,后者称为守护线程。守护进程同理。
此外,多线程爬虫中,还会涉及到HTTP连接池等问题,后面会详细描述。
2.多线程爬虫的设计
指向同一目标服务器的爬虫线程不宜过多,一是会造成目标服务器压力过大,二是在没有代理池的情况下,容易触发反爬虫机制,导致被封ip等。
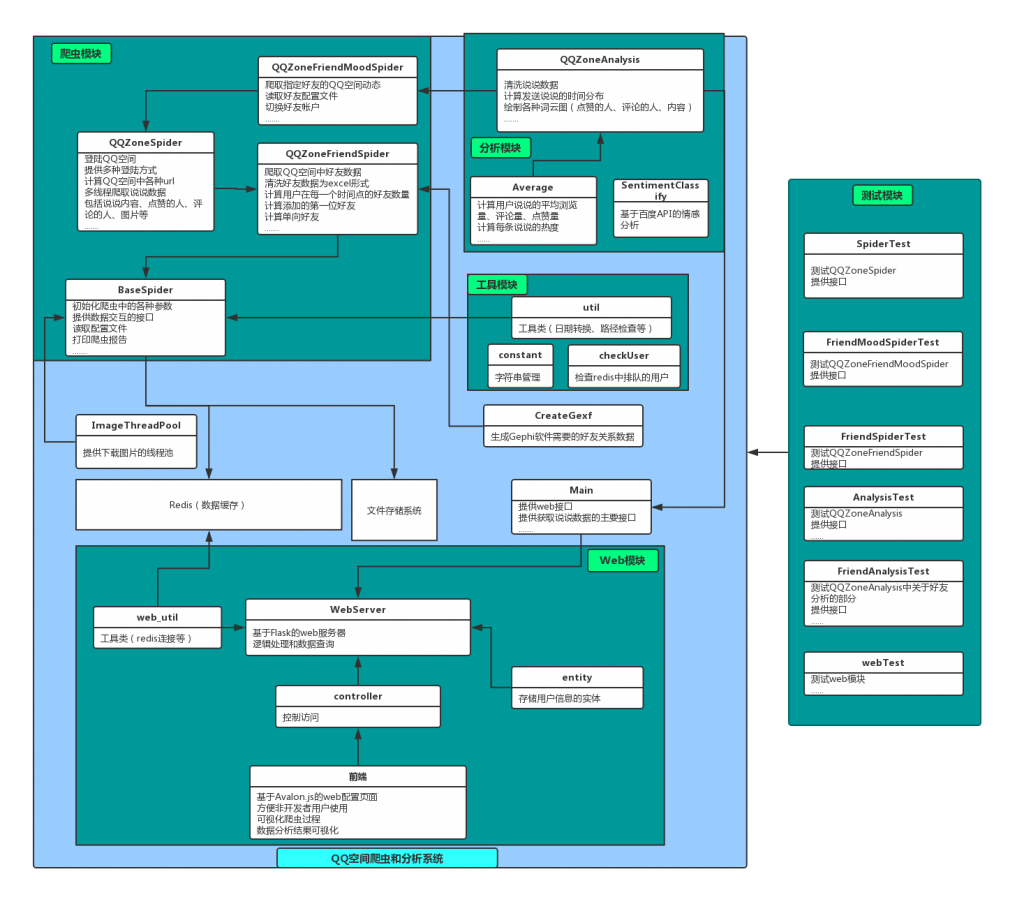
系统架构图
系统最终的架构如图所示。其中涉及到多线程的地方有:
- WebServer接收用户请求后,为避免阻塞请求,对每一位用户启动一个新守护线程(T1),调用main中提供的接口
- T1中启动两个线程,分别是获取用户动态数据的线程(T2)和获取用户好友数据的线程(T3),T2、T3为非守护线程,也就是T1要等待这两个线程执行完毕后再进行下一步。
- T2中开启多个子线程爬取QQ空间的动态,线程数量视动态数量而定,保证每个线程至少获取20条动态(太少的话不值得开启线程),线程数量最大值为10,这些线程都是非守护线程。
- T3中开启多个子线程获取好友数据。
- BaseSpider中初始化一个下载图片的线程池,ImageThreadPool(ITP),ITP中维护一定数量的线程,为整个项目提供异步保存图片的功能。因为保存图片也是属于IO操作,可以通过多线程优化,但是频繁创建线程的开销过大,且保存每一张图片的耗时很短,因此通过线程池来避免大量反复创建线程。
- T1在等待T2、T3执行完毕之后,在数据分析阶段可以开启多进程同时执行不同的数据分析任务。但是!Mac OS 不允许在子线程中开启新的进程(其它操作系统可以,已测试,可以在docker中使用),详情参考 Objective-C and fork() in macOS 10.13,尽管给出了解决方法,但是我尝试了修改环境变量的那种方法,并没有成功,所以这个功能我在代码中实现后并没有合并到主分支中,有兴趣的可以查看这个分支:QQZoneMood/tree/multiThread
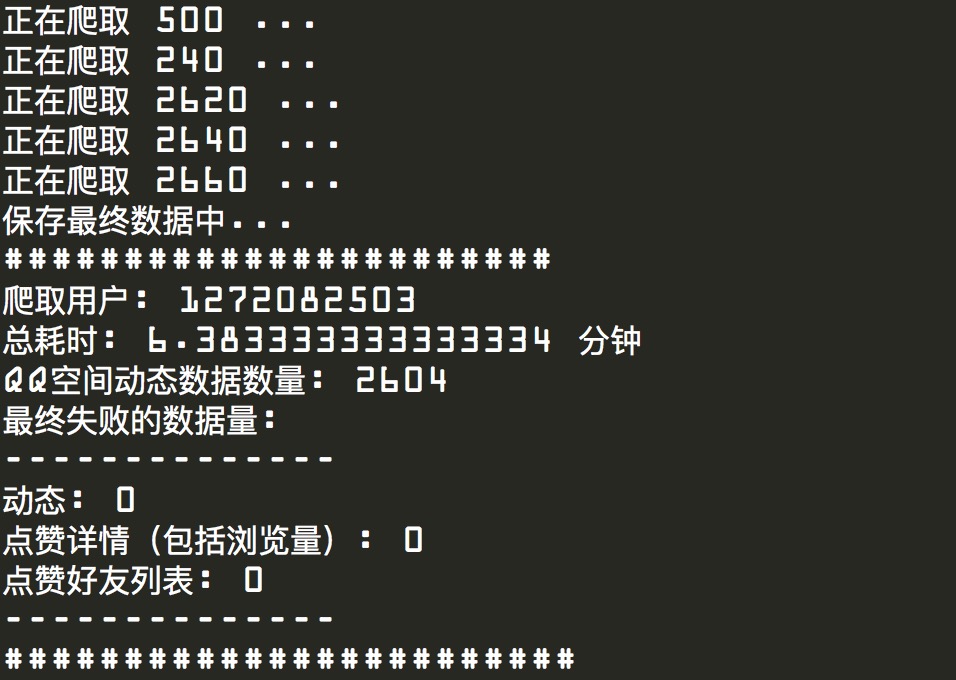
通过以上的多种方法,成功将爬取一个包含2000+条动态、1500左右的好友数量的用户数据的耗时从近一个小时压缩到4分钟左右。
3.线程和进程间通信
从第二节中可以发现,针对每一个用户,最多时有30个线程在获取数据或工作,为了对用户友好,这些线程需要及时向前端反馈获取数据的状态,最直观的就是展示进度条。
首先,线程之间可以直接通过内存来完成数据通信,通过维护类里的私有变量来及时保存和更新数据。比如在获取说说内容的10个线程中,每个线程都将数据存储在同一个list中,因为python不存在真正的多线程,所以这里不必考虑锁的问题。(进程做不到这一点,因为进程的内存是独立的)
但是,前端如何实时获取数据的状态呢?
如果是传统的web项目,可以通过session等机制来完成全局数据共享,但是这个项目一开始并没有打算写作web项目,爬虫部分是一个很完整的脚本程序,如果要使用session,对原来的代码更改太大。最终决定通过基于内存的数据库redis来完成通信。爬虫程序和web后端在redis中根据自定义的协议访问和维护不同的键值,来表示不同的状态。因为redis具有极高的读写速度,所以速度方面不存在瓶颈,因此很多web框架都可以使用redis来存储session,比如springboot, django。
因此我在redis定义了大量的键,爬虫程序在获取数据的过程中不断更新键值,web端通过轮询查询redis,及时获得反馈。(这里还可以优化,使用websocket代替轮询,可以节省大量资源,且websocket可以做到广播,即一次查询,推送给多个客户端,但是实现较为麻烦。)此外,web端也可以通过往redis中插入键值来控制运行中的线程,以此来实现停止线程等功能。
4.多线程与Http连接池
我们都知道,HTTP在建立链接的时候会先经过TCP的三次握手,爬虫程序因为存在大量的网络请求,所以如果每一次连接都需要三次握手,必然非常浪费时间,因此可以考虑使用http长连接,即keep-alive = true。但是,在多线程情况中,我需要建立多少个长链接?什么时候我可以重用链接呢?这里我不废话了,因为这篇博客写得太好了:【转载-译文】requests库连接池说明
直接分享一下爬虫启动前的代码吧:
self.req = requests.Session()
# 使用cookieJar管理cookie
self.cookies = cookiejar.CookieJar()
self.req.cookies = self.cookies
connection_num = 20 * SPIDER_USER_NUM_LIMIT
# 设置连接池大小
self.req.mount('https://', HTTPAdapter(pool_connections=5, pool_maxsize=connection_num))
self.req.mount('http://', HTTPAdapter(pool_connections=5, pool_maxsize=connection_num))
其中SPIDER_USER_NUM_LIMIT是我设置的允许同时在线的用户数量。这里的意思是,建立一个连接池,这个连接池允许同时和5个不同的host建立的长链接(因为我大致数了一下,这个爬虫程序会涉及到5个不同的host);连接池允许的最大长连接数量是 20 * SPIDER_USER_NUM_LIMIT(每个用户大约分配20个连接)。
5.总结
python中的多线程和多进程的使用都非常方便,在大多情况下,并发都能有效提高爬虫的效率,节省时间。但是并发也不一定完美,比如我之前在爬虫中有个功能,是在爬虫意外中断或停止后从redis中重新读取数据,根据已有的数据数量来确定还需要获取的数据数量,从而在中断处恢复程序。但是在多线程情况中,由于爬取到的数据顺序比较混乱,之前恢复数据的功能就无法使用。
这个项目最初就是一个文件,几十行代码,后来出于兴趣,不断的添加新的功能,不断的修改完善,把它变成了一个包含10几个类、上万行代码的小系统。写一个能获取数据的脚本很简单,但是要想让普通用户能使用却很复杂,因为前者只需要考虑一种成功的情况,后者却需要再考虑N种失败的情况。特别是爬虫程序,这种存在不确定性的程序,所以最终代码里可能有近一半都是在处理各种异常情况和错误,比如仅登陆方式我就写了三种。但是尽管这样,不可避免的,程序总会存在bug…

点击量:61391

13 条评论
远哥制造 · 2019年8月22日 下午1:40
发现了不少骚操作,是大佬,wsl!
蔡徐坤 · 2019年8月24日 上午11:12
大哥 接口不给用吗-.-
maicius · 2019年8月24日 上午11:48
什么的接口?
成龙 · 2019年12月5日 上午11:59
QQ空间那个为什么我的数据分析一直卡着出不来,一直在分析,朋友的qq却能出来?
maicius · 2019年12月5日 下午8:54
好友的进度条卡着不动的话其实也是爬取完了的,因为有好友的数据无法获取,进度条只显示了成功获取的数量。如果结果没有图片的话,应该是出bug了,暂时不知道原因,因为我这里很难复现
里克贝斯 · 2020年1月7日 下午10:28
前辈请问如何处理数据构建好友社交网络呢
maicius · 2020年1月8日 下午2:17
你是指的构建出一张以好友为节点的图吗?这个功能我是实现了,但是接口没有整理好,近期我会整理一下,你可以先参考一下:https://github.com/Maicius/QQZoneMood/blob/master/src/visual/CreateGexf.py
里克贝斯 · 2020年1月8日 下午5:47
感谢解答
mkdir700 · 2020年1月18日 下午10:21
写得很好,支持支持
IKE · 2020年5月4日 下午5:50
想请问一下说说数据表的表头各列什么含义?(求解答)
lxh · 2021年4月29日 下午10:05
docker部署后只能从3000端口进前端,然后只有二维码那一页,大佬能指点一下吗
maicius · 2021年4月30日 下午11:56
正常情况下应该是通过5000端口,进入配置爬虫的页面。3000端口是数据展示项目用的,在URL没有传入有效的参数时就会默认跳转到二维码那一页
Python 加速计算密集型任务经验总结 – 小麦冬 · 2019年8月24日 下午3:58
[…] 上一篇文章总结了Python在IO密集型任务中的加速经验,这篇文章则介绍如何在计算密集型任务中进行加速。 […]