-
- 在数据处理中使用正则做数据清洗
还记得几年前第一次看见两个室友讨论一个匹配网址的正则表达式的时候,我看了一眼代码, 代码肯定记不住了,但是第一反应我始终记得,“这tm什么东西?!”
附:匹配网址的正则写法大致如下:
^(?=^.{3,255}$)(https?:\/\/)?([w]{3}.)?([a-zA-Z0-9]+(.|\/))+[a-zA-Z0-9]*
对于一个崇尚代码可读性的人来说,正则实在是太不友好了。但是在写了几十个爬虫之后,越来越体会到了正则的重要性和优越性,所以决定好好整理一下。
- 本文所用的示例代码
正则的语法
正则难就难在语法太简洁,太奇怪,刚开始接触的时候很容易就被吓跑了,但是没办法,要用正则,必须得记住这些语法(也没必要一开始就全部记住,需要用的时候查一下就好了)。 这里就直接引用菜鸟教程的语法介绍了。正则表达式语法–菜鸟教程
下面介绍一些不是很常见的语法
- 贪心匹配与非贪心匹配
先回忆一下这几个符号的作用:符号 作用 + 匹配前面的字符串一次或多次 * 匹配前面的字符串零次或多次 ? 匹配前面的字符串零次或一次 +和*默认都是贪心模式,即会尽可能的匹配更多的字符 非贪心模式就是最小匹配,在+或*之后加一个?就进入非贪心匹配模式
举个栗子(本文中所有代码都放在github上)
class Reg():
def __init__(self):
# 这是我从空间里随便复制的一条说说
self.test_html = '下面才是正文<pre style="display:inline;" class="content">看“空城计”的三个阶段:“哇,诸葛亮好厉害”;“假的,没意思”;“兔死狗烹,弹尽弓藏……不愧是孔明”</pre>'
def test_greedy(self):
print('Greedy===========================')
print(re.findall(re.compile('<.*>'), self.test_html))
print('No Greedy===========================')
print(re.findall(re.compile('<.*?>'), self.test_html))
输出如下:
Greedy===========================
['<pre style="display:inline;" class="content">看“空城计”的三个阶段:“哇,诸葛亮好厉害”;“假的,没意思”;“兔死狗烹,弹尽弓藏……不愧是孔明”</pre>']
No Greedy===========================
['<pre style="display:inline;" class="content">', '</pre>']所以,贪婪模式下,<.*>匹配到了从第一个< 到最后一个> 的所有字符;<.*?>则是匹配最相近的一组括号 但是,一般我们要提取的都是文字内容(innerHTML),而不需要两边的修饰符,这种情况,就需要另外一种有趣的语法:非获取匹配
- 非捕获元 也叫非获取匹配,顾名思义,就是只匹配,但是不获取,它具体有以下几种语法:
?: pattern
用以消除圆括号的分组,如需要同时匹配诸葛亮和诸葛孔明,正常写法是 ‘诸葛(亮|孔明)’, 但是这样做使’亮’和’孔明’也被单独保存,如果不想保存,那就使用?:来消除,写法如下: ‘诸葛(?:亮|孔明)’
eg:
def test_capture(self):
self.words = '诸葛亮就是诸葛孔明不是诸葛瑾'
reg_capture = '诸葛(亮|孔明)'
reg_no_capture = '诸葛(?:亮|孔明)'
print("Capture===========================")
print(re.findall(re.compile(reg_capture), self.words))
print("No Capture========================")
print(re.findall(re.compile(reg_no_capture), self.words))输出如下:
Capture===========================
[‘亮’, ‘孔明’]
No Capture========================
[‘诸葛亮’, ‘诸葛孔明’]
?= pattern
非获取匹配 + 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,但该不捕获pattern
eg:
def test_capture(self):
self.words = '诸葛亮就是诸葛孔明不是诸葛瑾'
reg_capture = '诸葛(亮|孔明)'
reg_no_capture2 = '诸葛(?=亮|孔明)'
print("Capture===========================")
print(re.findall(re.compile(reg_capture), self.words))
print("No Capture========================")
print(re.findall(re.compile(reg_no_capture2), self.words))输出如下:
Capture===========================
[‘亮’, ‘孔明’]
No Capture========================
[‘诸葛’, ‘诸葛’]
?! pattern
非获取匹配 + 正向否定预查,与前面相反,在任何不匹配pattern的字符串开始处查找字符串,并且不捕获pattern
eg:
def test_capture(self):
self.words = '诸葛亮就是诸葛孔明不是诸葛瑾'
reg_capture = '诸葛(亮|孔明)'
reg_no_capture3 = '诸葛(?!亮|孔明)'
print("Capture===========================")
print(re.findall(re.compile(reg_capture), self.words))
print("No Capture========================")
print(re.findall(re.compile(reg_no_capture3), self.words)) 输出如下:
Capture===========================
[‘亮’, ‘孔明’]
No Capture========================
[‘诸葛’]
此时No Capture匹配到的是诸葛瑾
?<= pattern
非获取匹配 + 反向肯定预查,在匹配到pattern的地方开发反向预查,并且不捕获pattern
?<! pattern
非获取匹配 + 反向否定预查
如果理解了前面几个,理解这两个就比较容易了,再举个简单的栗子
eg.
def test_capture(self):
self.reverse_words = '大司马'
self.reverse_wrong_words = '小司马'
reg_no_capture_reverse = '(?<=大)司马'
reg_no_capture_inorder = '司马(?=大)'
print("反向肯定预查============================")
print(re.findall(re.compile(reg_no_capture_reverse), self.reverse_words))
print(re.findall(re.compile(reg_no_capture_reverse), self.reverse_wrong_words))
print("反向否定预查============================")
print(re.findall(re.compile(reg_no_capture_reverse_negative), self.reverse_words))
print(re.findall(re.compile(reg_no_capture_reverse_negative), self.reverse_wrong_words))
print("正向预查=============================")
print(re.findall(re.compile(reg_no_capture_inorder), self.reverse_words))输出如下:
反向肯定预查============================
[‘司马’]
[]
反向否定预查============================
[]
[‘司马’]
正向预查=============================
[]
- 最后,回到前面,使用正则提取innerHTML
class Reg():
def __init__(self):
# 这是我从空间里随便复制的一条说说
self.test_html = '下面才是正文<pre style="display:inline;" class="content">看“空城计”的三个阶段:“哇,诸葛亮好厉害”;“假的,没意思”;“兔死狗烹,弹尽弓藏……不愧是孔明”</pre>'
def test_innerHTML(self):
print('使用正则提取html innerHTML===================')
print(re.findall(re.compile('(?<=<pre style="display:inline;" class="content">).*(?=</pre>)'), self.test_html))输出如下:
使用正则提取html innerHTML===================
[‘看“空城计”的三个阶段:“哇,诸葛亮好厉害”;“假的,没意思”;“兔死狗烹,弹尽弓藏……不愧是孔明”’]
- 附:python 还有一个叫BeautifulSoup的库可以解析网页,要简单很多,不推荐直接使用正则,有点耽搁时间
正则表达式在编程语言中的实现
正则表达式是一类通用的字符串处理规则,所以在各类语言的具体实现中,都会严格遵守其语法。除此之外,正则表达式主要有三个方法——匹配、查找、替换。根据不同的语言的特点,这几个方法在实现上会有一点不同。 下面以python re库为例,介绍几个常用的函数(所有语言都会实现这几个函数,只是名称不一样)。
- 1.模版 pattern
pattern是一个很重要的对象,就是需要匹配的字符串模板,如[w]{4}这样的语法,其实现严格遵守正则表达式的语法规则,python 中使用 re.compile()函数将普通字符串转化为pattern(简单的说,就是让[]{}.*?啊这些特殊符号生效,这一点比较奇葩的是js,可能因为js的是弱类型语言,它的正则不compile也能有效)。 - 2.匹配match
函数原型: def match(pattern, string, flags=0)
作用: 从字符串开始的地方,检查字符串是否与pattern一致,如果找到就返回一个包含查找到的字符串的match对象; 如果没有找到,则返回None 这里是python和其它Java\C++\Js这些语言一个不同的地方,其它语言通常是直接返回True或False,而python是返回了匹配到的对象或None,这样点话,match功能就与search()和findall()有些重复了。 - 3.搜索 search() 函数原型: def search(pattern, string, flags=0) 返回值:包含查找到的第一个字符串的match对象,如果没有找到,则返回None为了详细描述search与 match的不同,我写了一个例子:
class Reg():
def __init__(self):
self.right_phone_num = '13590210076'
self.wrong_phone_num = '12345678901'
self.wrong_phone_num_tail = '135902100761'
self.wrong_phone_num_head = '1135902100761'
self.multi_phone_num = '13590210676, 18996720675, 18996720675'
self.reg = '1[3,5,7,8][0-9]{9}'
self.pattern = re.compile(self.reg)
def test_match_search(self):
print('Right Phone Number=========================')
print(re.match(self.pattern, self.right_phone_num))
print(re.search(self.pattern, self.right_phone_num))
print('Wrong Phone Number=========================')
print(re.match(self.pattern, self.wrong_phone_num))
print(re.search(self.pattern, self.wrong_phone_num))
print('Wrong Phone Number Tail=========================')
print(re.match(self.pattern, self.wrong_phone_num_tail))
print(re.search(self.pattern, self.wrong_phone_num_tail))
print('Wrong Phone Number Head=========================')
print(re.match(self.pattern, self.wrong_phone_num_head))
print(re.search(self.pattern, self.wrong_phone_num_head))
print('Multi Phone Number=========================')
print(re.match(self.pattern, self.multi_phone_num))
print(re.search(self.pattern, self.multi_phone_num))
if __name__ == '__main__':
# 从输入的字符串中匹配正确的手机号码
reg = Reg()
reg.test_match_search()得到的结果如下:
Right Phone Number=========================
<sre.SREMatch object; span=(0, 11), match=’13590210076′>
<sre.SREMatch object; span=(0, 11), match=’13590210076′>
Wrong Phone Number=========================
None
None
Wrong Phone Number Tail=========================
<sre.SREMatch object; span=(0, 11), match=’13590210076′>
<sre.SREMatch object; span=(0, 11), match=’13590210076′>
Wrong Phone Number Head=========================
None
<sre.SREMatch object; span=(1, 12), match=’13590210076′>
Multi Phone Number=========================
<sre.SREMatch object; span=(0, 11), match=’13590210676′>
<sre.SREMatch object; span=(0, 11), match=’13590210676′>总结:
search是从左边开始,对字符串进行检索,找到符合pattern的字符串就立即返回。
match主要是进行匹配,对输入的字符串看是否满足pattern的模式, 但是python这里只实现了检查头部,却没有检查尾部,如果要完整匹配的话,可以使用fullmatch(pattern, string, flags=0)
- 4.查找全部 findall
函数原型: def findall(pattern, string, flags=0)
作用:查找string中所有符合pattern的字符串,返回一个list。
因为findall返回的是一个包含匹配到的字符串的list,而不是match对象,所以使用起来会简单很多
eg.
class Reg():
def __init__(self):
self.multi_phone_num = '13590210676, 18996720675, 18996720675'
self.reg = '1[3,5,7,8][0-9]{9}'
self.pattern = re.compile(self.reg)
def test_findall(self):
print('Find all Multi Phone Number=========================')
phone = re.findall(self.pattern, self.multi_phone_num)
print(','.join(phone))
运行结果如下:
Find all Multi Phone Number=========================
13590210676,18996720675,18996720675- 5.替换, sub\subn(大多数语言中叫replace)
函数原型:
def sub(pattern, repl, string, count=0, flags=0)
def subn(pattern, repl, string, count=0, flags=0) 作用:两者的主要的区别就是前者直接返回替换后的字符串,后者返回一个元祖,(new_string, number),number表示被替换的字符串的数量。
eg:
class Reg(): def __init__(self): self.multi_phone_num = '12345678901,13590210676, 18996720675, 18996720675' self.reg = '1[3,5,7,8][0-9]{9}' self.pattern = re.compile(self.reg) def test_sub(self): print("Sub =============================") print(re.subn(self.pattern, '正确的电话号码', self.multi_phone_num)) print(re.sub(self.pattern, '正确的电话号码', self.multi_phone_num)) print(re.subn(self.pattern, '正确的电话号码', self.multi_phone_num, 2)) print(re.sub(self.pattern, '正确的电话号码', self.multi_phone_num, 2)) if __name__ == '__main__': reg = Reg() reg.test_sub()运行结果如下:
Sub =============================
(‘正确的电话号码, 正确的电话号码, 正确的电话号码’, 3)
正确的电话号码, 正确的电话号码, 正确的电话号码
(‘正确的电话号码, 正确的电话号码, 18996720675’, 2)
正确的电话号码, 正确的电话号码, 18996720675
- python中re.sub()与str.replace的区别
python的string中也实现了replace,起到了与re.sub类似的作用,唯一不同的是,replace不能使用正则,sub可以使用正则。 类似的,re.split可以使用正则,但是str.split不能。
正则表达式的应用
正则的应用很多,这里只介绍几个常用的
- 字符验证 Web开发中很常用,用户注册、登陆、输入时经常需要正则来验证输入是否正确。只要是有规则的字符串,都可以利用正则表达式来验证。下面给几个常用的正则:
1.验证email:
[0-9a-zA-Z]+@[0-9a-zA-Z]+\.com
解释:[0-9a-zA-Z] 表示只能为数字或字母,+ 表示一次或多次,@[0-9a-zA-Z]+.com是匹配@qq.com,@163.com这样的情况。
2.验证手机号码:
1[3,5,7,8][0-9]{9}
解释: 手机号一般都是以1开头,第二位是3,5,7,8,后面9位数字
3.验证网址:
^(?=^.{3,255}$)(https?:\/\/)?([w]{3}.)?([a-zA-Z0-9]+(.|\/))+[a-zA-Z0-9]*
验证网址的正则很多,因为完全考虑完太过复杂,所以就只写了个简单的。此正则能验证如下形式的网址: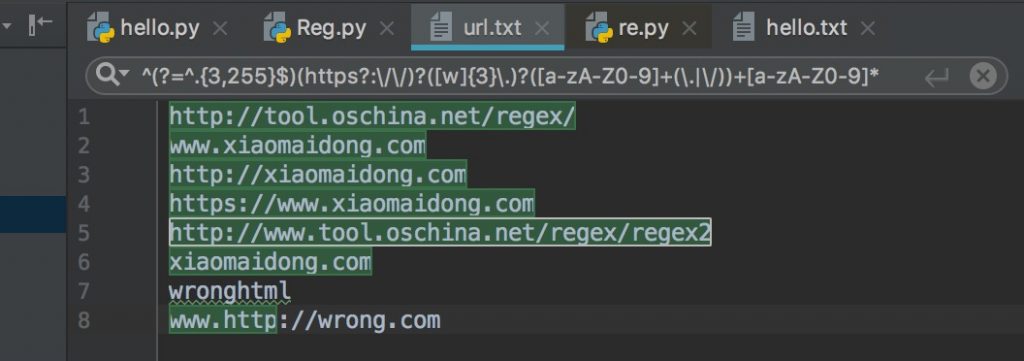
4.验证中文
[u4E00-u9FA5] - 数据清洗
在处理各种自然语言的时候,可以用正则快速去除大量没有意义的词语。特别是需要抓取整个网页内容,而网页结构又不固定时,利用sub快速替换固定内容非常有用。 - 解析网页内容(与BeautifulSoup类似,但是更为原始)
-
总结
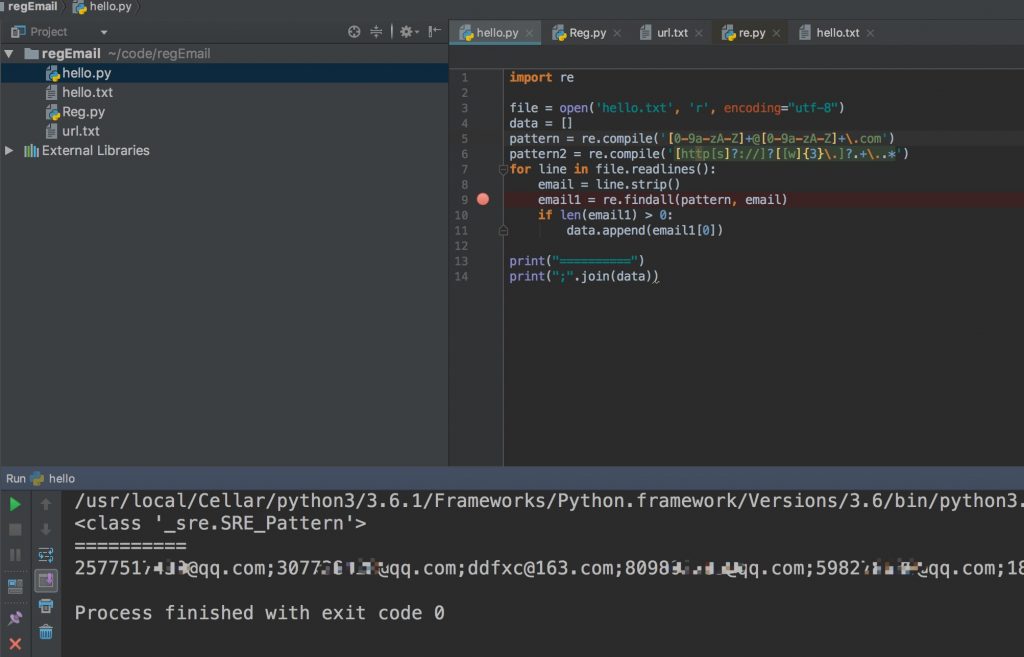
正则的应用非常广泛,即使在日常生活中也如此。比如最近很多人在知乎上留邮箱让我发python的PPT,一个一个的复制邮箱显然很浪费时间,所以我把文字全部复制下来,使用正则提取邮箱邮箱。。。
- 更多关于正则的使用,可以参考这个项目:UniversityRecruitment-sSurvey
点击量:17009