有一天我在网上看到了张雪峰老师在《演说家》上的演讲,就是他怼那个人“所以你的企业不是世界五百强”那个演讲,他说了一句话让我印象很深刻,大意就是“什么样的企业会去齐齐哈尔大学招聘,什么样的企业会去清华大学招聘?”我仔细思考了一下,决定用严肃的数据来回答这个问题。
我主要从两个角度去寻找高校与招聘企业的关系,一是高校的类别,二是高校的地理位置。
截止2018年10月29日,一共获取了69所高校(其中C9高校9所, 985高校 20所, 211高校17所, 普通一本12所, 普通二本11所),149962条招聘数据;企业方面爬取了世界五百强、中国五百强、中国互联网企业100强、世界咨询业100强等9种名单。
一分钟动态的看完这个调查报告: 戳这里
所有可视化数据地址:戳这里
以下是我们最终分析得到的比较有价值的数据
1.不同类别高校的校园招聘企业数量分布情况
注意:所有数据均为平均数据





2. 全国部分城市211(包括985、C9)高校校园招聘企业平均数量分布
注:黄点面积与数量多少呈正相关,没有黄点的城市表示没有数据;
平均的意思是指一个城市若有两个及两个以上211高校,该数据为总招聘企业/211高校数量
该数据中的招聘数量指所有企业,未对企业进行分类
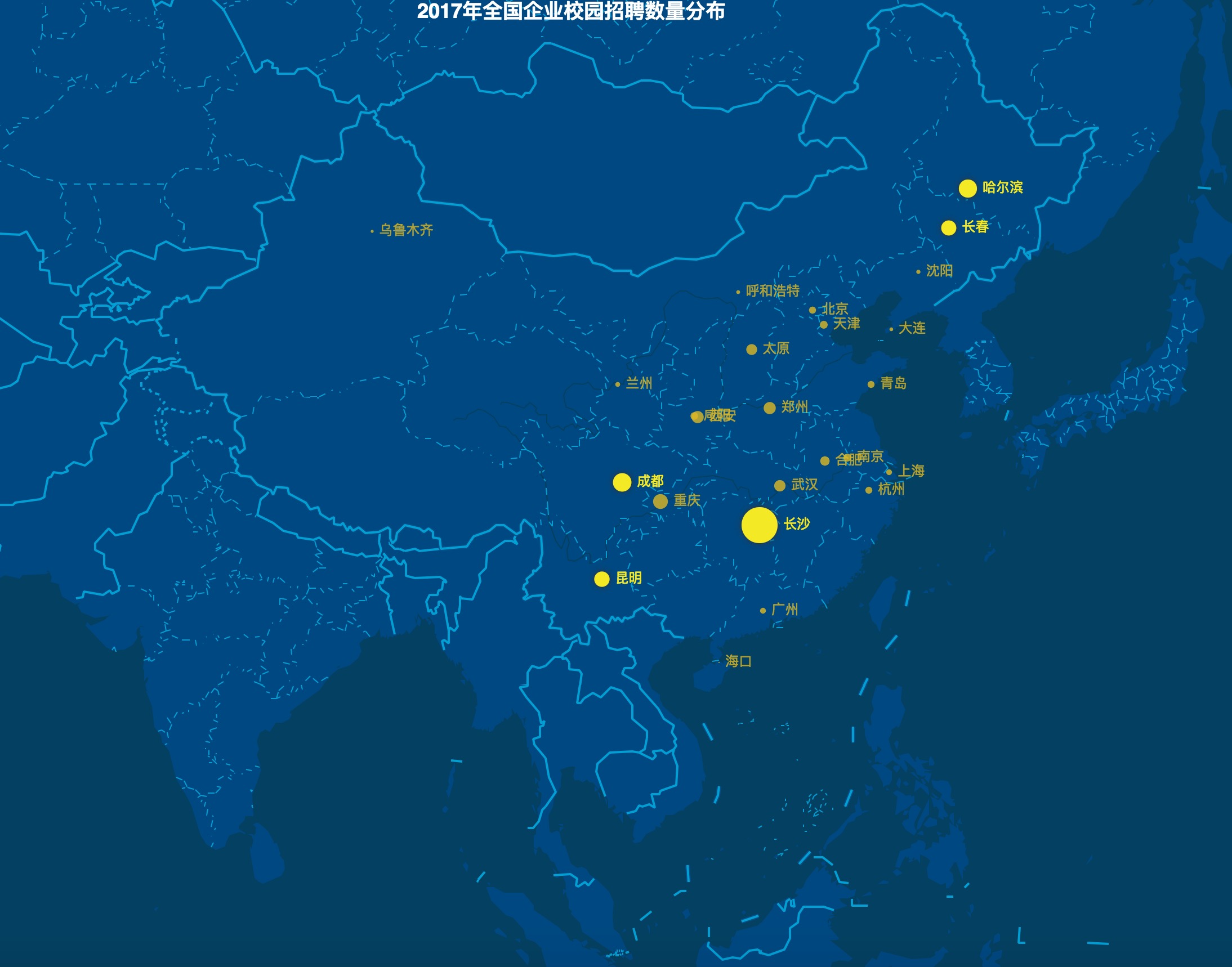
这份数据非常令我意外,我本来以为数量最多的会是北上广等超一线大城市,结果排名前五的城市分别是(‘长沙’, 3201), (‘成都’, 1637), (‘哈尔滨’, 1607), (‘贵州’, 1604), (‘昆明’, 1358)。但是排名倒数的五个城市无一例外,都是比较偏远的城市:(‘沈阳’, 372), (‘呼和浩特’, 338), (‘大连’, 328), (‘乌鲁木齐’, 260), (‘海口’, 107),由于感觉这部分数据可能误差较大,所以就只公布这么一些。
3. 校园招聘与时间的关系
在去年9月,刚刚保完研的我准备去体验一下校招,结果一个同学给我说,大型IT公司的校招差不多都招完了。于是我就顺便做了一份这个图,来看一下企业到底在什么时候进行招聘。

可以看出秋招的规模大于春招,在暑假期间已经有了一些零星的招聘会,9月出开学之后就逐渐升温,并在国庆节期间迎来一个短暂的休息期,还没准备好简历的同学一定要在这个时候做好准备,国庆节之后便是校园招聘的高峰期。(大概在11月的时候,我在校园里逛的时候,听到一哥们儿说,他这周就去把简历做好,他旁边的女生怼他一句,秋招都要结束了你才开始。)
- 下面开始介绍一下整个项目的情况
数据的来源
- 1.招聘数据
显然我不可能跑到每个高校去看有什么企业到那里去招聘,但是很多高校都会有专门用于发布招聘信息的就业信息网,于是我决定从这些就业信息网入手。高校的就业信息网发布的招聘信息大致分为三种:
1.专场宣讲会(单个企业到高校开展宣讲会并进行招聘)
2.组团招聘会(多个企业组队到高校同时进行招聘,包括高校举办的大型毕业生双选会)
3.在线招聘(网站仅分布企业的招聘信息,企业并不会到高校现场招聘)
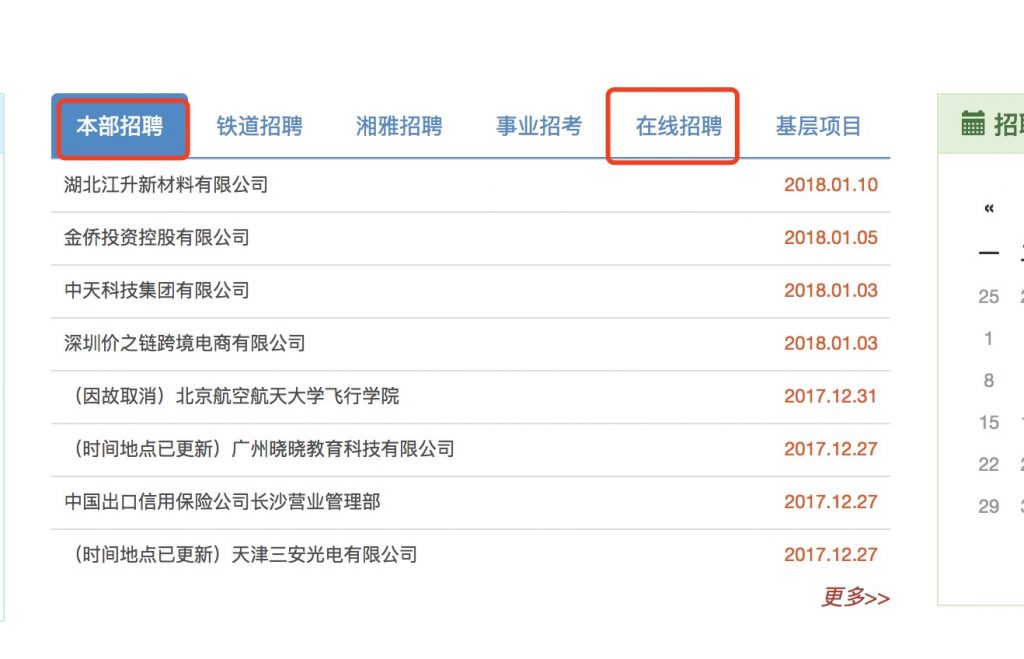
图为中南大学的就业信息网,其中有明显区分在线招聘和本部招聘
-
因为我想要的数据是到各个高校现场招聘的企业数据,所以只选取了1和2。所以抓取的网站仅限于有明确区分在线招聘与现场招聘的高校就业信息网。
- 2.公司的分类(点击可查看数据来源)
- 中国五百强
- 世界五百强
- 美国500强
- 中国私营企业500强
- 中国互联网企业100强
- 中国服务业100强
- 中国制造业500强
- 世界投资机构100强
- 咨询业75强
如有错误,欢迎指正
一些基本标准
本文的各种分析结果都是基于这几条标准进行的:
- 世界500强、中国500强、美国500强等公司名单来源于财富网、中华工商网等网站,均是2017年最新数据
- 比较特殊的是世界投资机构100强和咨询业75强,相关数据来源已给出,如有错误,欢迎指正
- 各种500强的子公司/下属机构,依然判断为500强,所以会出现中南大学的中国500强数量超过500的情况,比如中建一局和中建二局分别到中南大学开宣讲会,那么算两次
- 所有数据为2017年1月1日至2017年12月31日出现在各大就业信息网的数据
- 共分了五个大学类别,C9\985\211\一本\二本, 各类别之间不重复,如哈尔滨工业大学归为C9,不在985、211、一本里重复统计;四川大学记在985里,不在211、一本里重复统计。
技术路线
- 数据获取——python爬虫
各高校就业信息网结构不一,所以基本上对每个网站都需要单独的编写爬虫。主要是用的库是requests, 静态HTML使用BeautifulSoup或正则表达式进行解析,特别喜欢post返回的json数据。这期间编写了大量的工具函数和统一接口来简化爬虫,但是关键的结构分析还是得手动。
最终大约写了80个爬虫,还是比较累 - 数据存储– redis + json
提供了两个数据存储的接口,一是将每条解析得到的数据都迅速存入redis,二是在爬虫结束前将整个大学的数据保存到json文件。这样做一是为了避免数据丢失,二是为了方便没有配置数据库的同学也能加入这个项目。此外,写了大量的异常处理用于避免爬虫中断时数据丢失。 - 数据分析
因为获取到的只是就业信息网上挂出来的招聘信息,这些招聘信息的标题取得千奇百怪,所以最大的难点在于如何从复杂的新闻中获得准确的企业名称,从而可以对企业进行分类。
各种类型的招聘新闻标题
- 这部分涉及自然语言处理,我对机器学习分类器在自然语言处理上的应用尚不熟悉,在观察了大量的新闻标题后,我决定硬编码…
首先,我从各种企业排名中获取到公司的完整名称,并利用结巴分词(jieba,一个很不错的中文分词库)和正则替换的方式,去掉标准公司名称中“公司”、“集团”这样的字眼。但是这样还是有两个问题。一公司的简称不统一,比如中国石油天然气集团公司简称为中石油,但是新闻标题中可能出现中石油,也可能出现中国石油,甚至全称…考虑到这样的公司也比较少,所以我决定手动添加。数据结构如下:{ "company_name": "中国石油天然气集团公司(CHINA NATIONAL PETROLEUM)", "short_name": [ "CHINA NATIONAL PETROLEUM", "中国石油天然气","中国石油天然气", "中国石油", "中石油" ] } shortname属性中的中石油是我手动添加的,类似的还有中石化、中建、中铁等 在使用short_name去匹配信息标题时,short_name中的所有简称都会逐一去匹配,匹配成功则立即中断,防止重复匹配。二是简称可能会错误匹配,比如京东方和京东,这是两家不同的公司,但是在匹配的时候 “京东”这个关键字会匹配到“京东方”,所以我又决定再添加一个属性,叫“wrong_name” 最终得到的数据结构如下:
{ "company_name": "京东集团", "short_name": [ "京东"], "wrong_name":[ "北京东", "京东方"] } 比如在“京东方科技有限公司近期到我校招聘”这样的标题中,使用short_name中的字段“京东”去匹配,匹配成功, 但是又检查新闻标题中包含了包含“京东方”字样,所以判断该标题中的公司不是京东。 - 数据可视化
主要使用jquery + echarts.因为对懒得搭建完整的网站,所以直接将数据分析的结果存为了js文件(准确的说是把数据存为了一个js变量放在js文件里),再从html页面引入.
总结
从技术上而言整个项目还是比较简单,但反复编写大量爬虫的过程也有些枯燥和乏味,并且由于很多网站在不断的改版,导致爬虫后期的维护也比较麻烦和心累。数据不可避免的存在误差,一是因为很多学校的就业信息不全,比如很多企业会直接到高校里具体的某所学院进行招聘,这种信息不会挂在就业信息网上;二是技术上可能的疏忽。所以我对大多数数据都采用了求平均数的方式来尽量减少误差。
所有通过爬虫获取到的数据都以json的形式放在了这里,因为个人精力有限,所以欢迎有兴趣的同学来下载、挖掘。
项目参与者
麦子,南京大学软件学院研究生
Github: Maicius
冉哲东,四川大学计算机学院学生
Github: WallfacerRZD
刘航,四川大学机械学院学生
迟阔,南京大学软件学院研究生
Github: Ch1Ku0
周川,南京大学软件学院研究生
Github: TheFristTheLast
————
项目Github地址:UniversityRecruitment-sSurvey
点击量:56899
4 条评论
孟中原 · 2018年1月4日 下午7:35
麦子学长666,python是学长自学的吗?
maicius · 2018年1月4日 下午8:50
以前小学期有python课
关于国家级大创,这里有一些有趣的数据 – 小麦冬 · 2018年2月4日 下午3:49
[…] 这两年花掉经费最多的是中南大学,我真的一点都不意外,因为之前因为之前我搞的一个校园招聘的数据调查,多项指标排第一的还是中南大学…15年一共审批的经费有218,924,819元, 16年有234,358,875元,增加了两千万左右,17年肯定还有增加。感谢国家,感谢学校,每年给这么多钱给我们玩…我的几张软件著作权和专利的申请费以及4台服务器一年的租金,都是从经费里扣的。 […]
硕士一年级课程设计合集(软件工程) – 小麦冬 · 2019年3月30日 下午1:35
[…] 云计算写了很多次小作业,这是第一次。作业的原型是大四时写的一系列爬虫,爬了69所高校招聘网站的招聘信息,找出哪些企业会到哪些学校招聘,详细的数据分析结果在这里。这门课我们主要是用spark对这些数据重写了一下分析,并利用websocket实时推送数据到前端,动态展示了2017年一年中不同类别高校平均每一天展开的校园招聘数量,从视频中可以直观的发现不同高校在招聘规模上的差距,以及一年中春招和秋招的规模大小。 […]