我最近参与的一个项目中有一个功能是获取OCR的识别结果,相关接口由另外一家公司写好了,我们在服务器端通过WebService调用就行。然而该功能十分的耗时,平均每次请求大约要花10秒,所以我开始考虑使用并发来增加速度的问题。
业务场景描述
在审判领域,一个案件中会涉及诸多的图片材料,我们希望在法官从案件列表选择一个案件进行查看之后,就开始获取所有图片的OCR结果,避免法官在点击显示OCR之后出现长时间的等待,并且在获取ocr请求时,不应对用户的正常操作产生影响,即用户还可以进行其他的http请求。
前端并发
由于一开始我是负责的前端,所以我希望能从前端解决的问题就尽量在前端解决了。 我们都知道,服务器是默认多线程或多进程的,一个连接建立一个线程,所以只要在前端并发的发送请求给服务器就OK了,问题似乎很简单。
JS的“多”线程
这篇博客JavaScript 进阶(一)JS的”多线程”写得非常好
一开始我以为JS和python 一样没有真正的多线程,只是一个模拟的多线程,但实际上浏览器是支持多线程的,所以这也就有了我们熟悉的ajax异步,在执行ajax请求的Http连接的部分,浏览器另外开了一个线程。借用上述博客中的一张图示意如下:

但不管怎样,只要能实现我要的那种“同时扔出去几十个请求”的效果就OK。查了下资料,发现JS下实现多线程的方式,大概有两种
- Web Worker, HTML5的新特性,效果很好,但是似乎不支持ie8,所以放弃。相关资料比较全,所以这里就不多赘述了。
- Concurrent.Thread.js, 一个日本人写的库,相关资料比较少,但是使用比较简单,且不需要像WebWorker一样把异步的代码全部放到单独的JS中,所以非常喜欢。
使用Concurrent.Thread.js作并发
简单的教程可以参考这篇博客: JavaScript 编写线程代码引用Concurrent.Thread.js
上面的博客中,给出了传递基本类型参数的方法:
Concurrent.Thread.create(f, 100000);
其中f为要执行的函数,100000为传递给f的参数,我模仿这个函数,写下了我的代码,大致如下:
Concurrent.Thread.create(function (selectedAjxh, tree_image_list) {
for (var i = 0; i < tree_image_list.length; i++) {
var wdId = tree_image_list[i];
console.log(wdId);
$.ajax({
url: baseUrl + '/getOcr',
type: 'post',
data: {
ajxh: selectedAjxh,
wdId: wdId,
},
success: function (data) {
if (check_result(data)) {
vm.tree_image_ocr_dict[data.object.wdId] = data.object.content;
}
}
})
}
}, vm.selectedAjxh, vm.tree_image_list);
就是传入两个参数,一个为int型,一个数组,因为使用的是avalon框架,所以参数都放在vm中进行传递。在这个线程中开启一个for循环,把ajax扔出去,进入另外一个异步,再把请求的结果保存到vm中。一切看起来都非常顺利,至少在少量图片测试的时候。
浏览器对前端并发的限制
上面代码在对少数图片的时候,确实执行比较流畅,能达到预期的效果,但是当图片数量变多时,用户新触发的请求需要花费非常长的时间等待(比如获取文档),用户体验极差。为了定位问题,到底是前端阻塞还是后端不堪压力,我找了很久,一度想甩锅给后端,最后终于在chrome开发者工具中的Timing中发现了这样一个东西
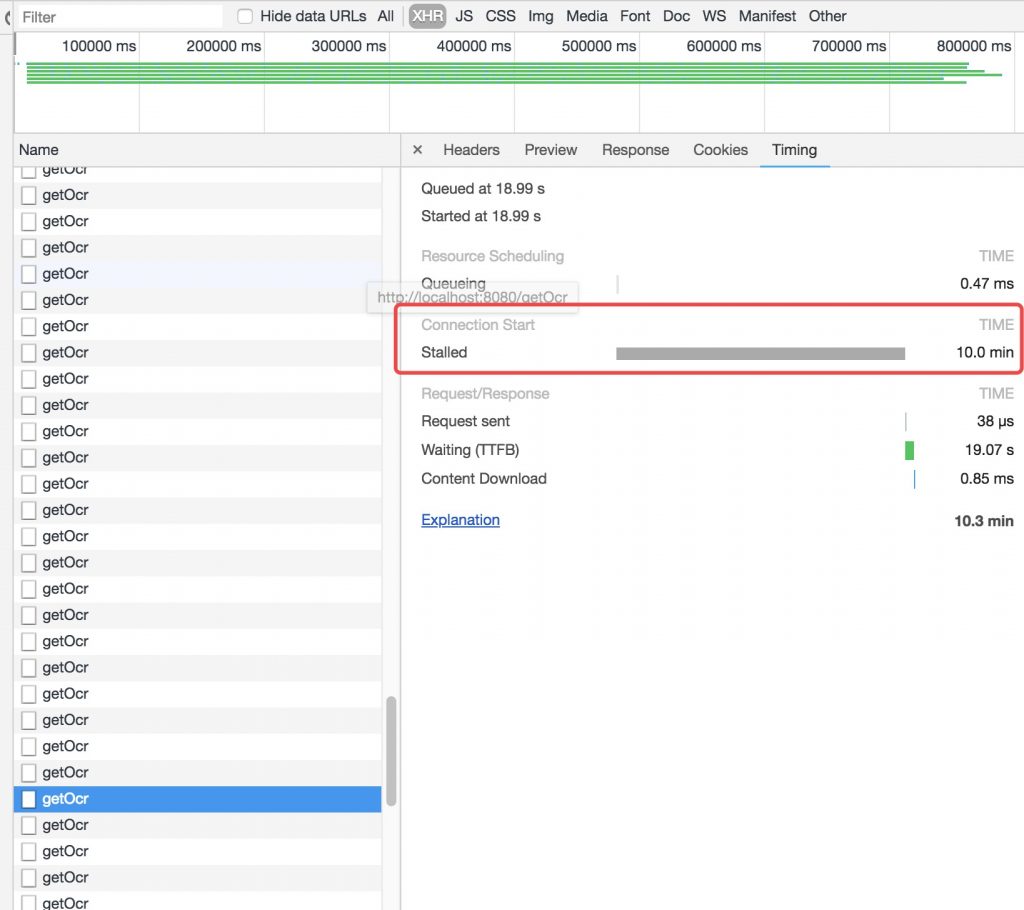
可以发现,其中Stalled的时间达到了惊人的10min,而实际的响应请求(后端处理)时间也就17s,也就是说这条请求在等了10分钟之后才发出去,这就导致了用户后面产生的请求等待的时间比这个还要长! 于是我开始思考为什么会产生这样的原因,于是我又翻到了这一篇博客:关于请求被挂起页面加载缓慢问题的追查(stalled 时间过长)
原来
浏览器对并发数量有限制!!!
浏览器对并发数量有限制!!!
浏览器对并发数量有限制!!!
重要的事情说三遍,其中各种浏览器的限制的数量如下:
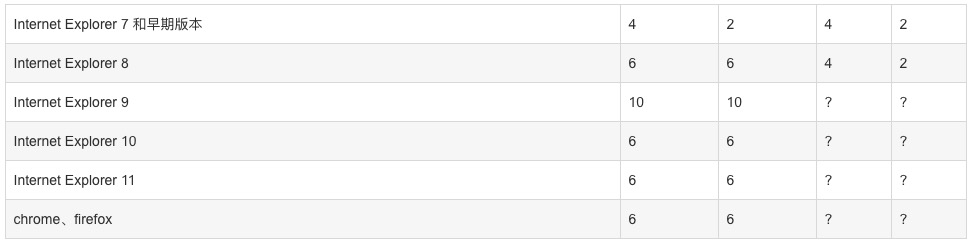
由于经常一次产生上百条请求,所以我决定放弃前端并发,改为后端并发。
后端并发
设计思路如下,
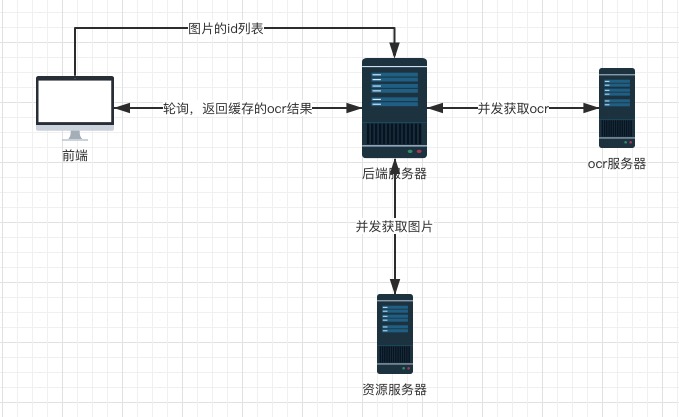
前端通过ajax将所有图片的id传给后端,后端开始并发的获取图片和图片的ocr结果,并将结果以HashMap的形式存储在Session中(使用Session主要是为了方便,如果愿意折腾,可以考虑使用NoSQL)。
Java并发的方案就不赘述了,这个资料挺多的,这里就讲一下多线程中使用Session中遇到的坑。
Java 多线程中使用Session作缓存
为了保证前端能及时获得已经处理好了的ocr结果,前端在发送请求后,记录下图片的数量,并使用setInterval向后端进行轮询请求(当然有兴趣的还可以折腾webSocket),后端不断的查询Session(Session中通过每个案件的id对图片进行分类,存储的形式是HashMap, 即: {案件id: {‘wdId0’: ”, ‘wdId1’:”,…}}), 如果返回的ocr的数量达到了图片的数量,则停止轮询。
这里我使用的是 implements Runnable的方式实现的多线程,通过在线程类中定义一个变量,对变量进行赋值的方式进行传参。相关代码如下:
public class OcrModel {
private int ajxh;
private UserModel user;
private HttpSession session;
....
}
public class OcrThread implements Runnable {
private OcrModel ocrModel;
@Override
public void run() {
...
...
session_key = ocrModel.getAjxh + ocrModel.getUser().getName() + "_ocr_map";
httpSession session = ocrModel.getSession();
ocrResultMap = ....
# 保存结果到全局Session中
session.setAttribute(session_key, ocrResultMap);
....
}
public void initOcrModel(HttpSession session, UserModel user, int ajxh) {
ocrModel = new OcrModel();
ocrModel.setAjxh(ajxh);
ocrModel.setUser(user);
ocrModel.setSession(session);
}
}
OcrThread ocrThread = new OcrThread();
ocrThread.initOcrModel(session, user, ajxh);
Thread thread = new Thread(ocrThread);
thread.start();
需要注意的是,initOcrModel中传入的session类型是HttpSession,不能使用HttpServletRequest request, 因为如果在多线程环境中使用request.getSession(), 获取到的Session会一直为null,因为HttpServletRequest 是线程不安全的,而HttpSession是线程安全的。
终于,这个问题被圆满解决。
附:分布式服务器中的Session共享
对项目负载均衡后,发现Session没有在各台机器之间共享,查了以下,Springboot 提供了一套比较方便的解决方案,即使用redis做缓存,下面做一个简单的介绍
- 1.在pom.xml中添加如下依赖:
<dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-redis</artifactId> <version>1.3.8.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> </dependency>2.建立RedisConfig类,添加以下注解
@Configuration @EnableCaching @EnableRedisHttpSession(maxInactiveIntervalInSeconds = 3600) public class RedisSessionConfig { } - 3.在application.yml中添加redis配置(根据自己的需要进行修改):
spring: redis: host: 127.0.0.1 port: 6379 password: Passw0rd需要注意的是,这里我只使用了一台服务器中的redis来做缓存,如果要把redis也做成分布式,可以参考这篇博客Spring Boot使用Spring Data Redis操作Redis(单机/集群)
此外,如果不考虑集成spring-data-redis,还可以单独使用ShardedJedis来实现redis的分布式,很久以前写过这样一段代码: JedisPoolManager.java
- 4.进行简单的测试
进行简单的登录操作(触发session保存)后,在redis-cli中发现了存在这样的键值:
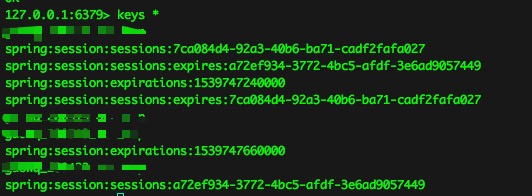
分布式服务器、多线程程序的Session共享问题
按照上面的步骤,确实完成了session的共享,比如用户的登录信息,都被保存在了session里。但是我保存的ocr信息却出现了神奇的bug,在多线程中调试发现,数据确实被存进去了,但是读取时却一直出现null,后来没有耐心调试了,就把缓存的任务交给redis了,如果有类似问题的同学可以交流以下。
附2: 使用nginx做负载均衡
1.安装nginx
2.修改配置文件中的upstream(一般需要自己添加该字段),即进行负载均衡的服务器地址:
upstream my_project {
least_conn;
server localhost:8080 weight=1;
server localhost:8000 weight=1;
}
其中localhost:8080和localhost:8000表示两个服务器;
weight表示权重,这里表示平均每两次请求中有一次访问localhost:8080,一次访问localhost:8000;
least_conn比较重要,表示把请求转发给连接数较少的服务器,具体算法可以搜索一下。3.修改location如下:
location / {
proxy_set_header Host localhost:80;
proxy_pass http://my_project;
}4.启动nginx,就可以通过localhost:80来访问服务器了
点击量:1698